![]()
Tested Material Used To Databricks-Certified-Data-Engineer-Professional Test Engine Exam Questions in here [Mar-2026]
Penetration testers simulate Databricks-Certified-Data-Engineer-Professional exam PDF
NEW QUESTION # 135
A small company based in the United States has recently contracted a consulting firm in India to implement several new data engineering pipelines to power artificial intelligence applications. All the company's data is stored in regional cloud storage in the United States.
The workspace administrator at the company is uncertain about where the Databricks workspace used by the contractors should be deployed.
Assuming that all data governance considerations are accounted for, which statement accurately informs this decision?
- A. Databricks notebooks send all executable code from the user's browser to virtual machines over the open internet; whenever possible, choosing a workspace region near the end users is the most secure.
- B. Cross-region reads and writes can incur significant costs and latency; whenever possible, compute should be deployed in the same region the data is stored.
- C. Databricks leverages user workstations as the driver during interactive development; as such, users should always use a workspace deployed in a region they are physically near.
- D. Databricks workspaces do not rely on any regional infrastructure; as such, the decision should be Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from made based upon what is most convenient for the workspace administrator.
- E. Databricks runs HDFS on cloud volume storage; as such, cloud virtual machines must be deployed in the region where the data is stored.
Answer: B
Explanation:
This is the correct answer because it accurately informs this decision. The decision is about where the Databricks workspace used by the contractors should be deployed. The contractors are based in India, while all the company's data is stored in regional cloud storage in the United States. When choosing a region for deploying a Databricks workspace, one of the important factors to consider is the proximity to the data sources and sinks. Cross-region reads and writes can incur significant costs and latency due to network bandwidth and data transfer fees.
Therefore, whenever possible, compute should be deployed in the same region the data is stored to optimize performance and reduce costs.
NEW QUESTION # 136
The view updates represents an incremental batch of all newly ingested data to be inserted or updated in the customers table.
The following logic is used to process these records.
MERGE INTO customers
USING (
SELECT updates.customer_id as merge_ey, updates .*
FROM updates
UNION ALL
SELECT NULL as merge_key, updates .*
FROM updates JOIN customers
ON updates.customer_id = customers.customer_id
WHERE customers.current = true AND updates.address <> customers.address ) staged_updates ON customers.customer_id = mergekey WHEN MATCHED AND customers. current = true AND customers.address <> staged_updates.address THEN UPDATE SET current = false, end_date = staged_updates.effective_date WHEN NOT MATCHED THEN INSERT (customer_id, address, current, effective_date, end_date) VALUES (staged_updates.customer_id, staged_updates.address, true, staged_updates.effective_date, null) Which statement describes this implementation?
- A. The customers table is implemented as a Type 2 table; old values are overwritten and new customers are appended.
- B. The customers table is implemented as a Type 1 table; old values are overwritten by new values and no history is maintained.
- C. The customers table is implemented as a Type 0 table; all writes are append only with no changes to existing values.
- D. The customers table is implemented as a Type 2 table; old values are maintained but marked as no longer current and new values are inserted.
Answer: D
Explanation:
The provided MERGE statement is a classic implementation of a Type 2 SCD in a data warehousing context. In this approach, historical data is preserved by keeping old records (marking them as not current) and adding new records for changes. Specifically, when a match is found and there's a change in the address, the existing record in the customers table is updated to mark it as no longer current (current = false), and an end date is assigned (end_date = staged_updates.effective_date). A new record for the customer is then inserted with the updated information, marked as current. This method ensures that the full history of changes to customer information is maintained in the table, allowing for time-based analysis of customer data.
NEW QUESTION # 137
A data engineer is implementing Unity Catalog governance for a multi-team environment. Data scientists need interactive clusters for basic data exploration tasks, while automated ETL jobs require dedicated processing. How should the data engineer configure cluster isolation policies to enforce least privilege and ensure Unity Catalog compliance?
- A. Create compute policies with STANDARD access mode for interactive workloads and DEDICATED access mode for automated jobs.
- B. Use only DEDICATED access mode for both interactive workloads and automated jobs to maximize security isolation.
- C. Allow all users to create any cluster type and rely on manual configuration to enable Unity Catalog access modes.
- D. Configure all clusters with NO ISOLATION_SHARED access mode since Unity Catalog works with any cluster configuration.
Answer: A
Explanation:
Unity Catalog enforces governance and data isolation through cluster access modes and compute policies. According to Databricks documentation, "Interactive clusters that multiple users share should use Standard access mode, while automated jobs and production pipelines should use Dedicated access mode for stricter isolation." Standard access mode allows multiple users to share the same compute resources but still respects Unity Catalog permissions. Dedicated access mode isolates the job run's execution environment, ensuring that data access is limited to the job's identity. Configuring these modes within compute policies enforces least privilege and ensures all compute complies with Unity Catalog security standards. Options A and C are incorrect because using only Dedicated clusters reduces resource efficiency, while "No isolation" clusters are not Unity Catalog compliant.
NEW QUESTION # 138
A table named user_ltv is being used to create a view that will be used by data analysts on various teams. Users in the workspace are configured into groups, which are used for setting up data access using ACLs.
The user_ltv table has the following schema:
email STRING, age INT, ltv INT
The following view definition is executed: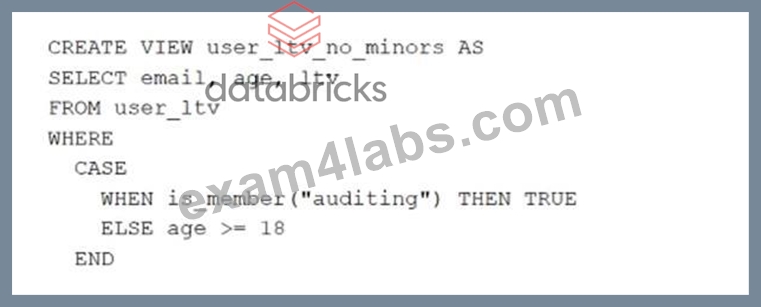
An analyst who is not a member of the auditing group executes the following query:
SELECT * FROM user_ltv_no_minors
Which statement describes the results returned by this query?
- A. All columns will be displayed normally for those records that have an age greater than 18; records not meeting this condition will be omitted.
- B. All columns will be displayed normally for those records that have an age greater than 17; records not meeting this condition will be omitted.
- C. All records from all columns will be displayed with the values in user_ltv.
- D. All values for the age column will be returned as null values, all other columns will be returned with the values in user_ltv.
- E. All age values less than 18 will be returned as null values all other columns will be returned with the values in user_ltv.
Answer: A
Explanation:
Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from Explanation:
Given the CASE statement in the view definition, the result set for a user not in the auditing group would be constrained by the ELSE condition, which filters out records based on age. Therefore, the view will return all columns normally for records with an age greater than 18, as users who are not in the auditing group will not satisfy the is_member('auditing') condition. Records not meeting the age > 18 condition will not be displayed.
NEW QUESTION # 139
A data engineering team is setting up a Git project to automate integration tests using Databricks Asset Bundles and the Git provider's CI/CD functionalities. When a pull containing changes to their pipleline is sent, they need to run a Job to test their data pipeline. What is the correct databricks bundle command sequence to be executed from the Git provider's CI/CD automation for this task?
- A. init, validate, deploy, run
- B. validate, deploy, run
- C. init, deploy, run, validate
- D. deploy, run, validate
Answer: B
Explanation:
The correct sequence is to first validate the bundle to ensure the configuration is correct, then deploy it to provision or update the defined resources, and finally run the job to execute the integration tests. This aligns with CI/CD best practices by catching configuration issues early and only running tests after a successful deployment.
NEW QUESTION # 140
A Delta Lake table in the Lakehouse named customer_parsams is used in churn prediction by the machine learning team. The table contains information about customers derived from a number of upstream sources. Currently, the data engineering team populates this table nightly by overwriting the table with the current valid values derived from upstream data sources.
Immediately after each update succeeds, the data engineer team would like to determine the difference between the new version and the previous of the table. Given the current implementation, which method can be used?
- A. Parse the Spark event logs to identify those rows that were updated, inserted, or deleted.
- B. Execute DESCRIBE HISTORY customer_churn_params to obtain the full operation metrics for the update, including a log of all records that have been added or modified.
- C. Parse the Delta Lake transaction log to identify all newly written data files.
- D. Execute a query to calculate the difference between the new version and the previous version using Delta Lake's built-in versioning and time travel functionality.
Answer: D
Explanation:
Delta Lake provides built-in versioning and time travel capabilities, allowing users to query previous snapshots of a table. This feature is particularly useful for understanding changes between different versions of the table. In this scenario, where the table is overwritten nightly, you can use Delta Lake's time travel feature to execute a query comparing the latest version of the table (the current state) with its previous version. This approach effectively identifies the differences (such as new, updated, or deleted records) between the two versions. The other options do not provide a straightforward or efficient way to directly compare different versions of a Delta Lake table.
NEW QUESTION # 141
A data engineer is building a streaming data pipeline to ingest JSON files from cloud storage into a Delta Lake table. The pipeline must process files incrementally, handle schema evolution automatically, ensure exactly-once processing, and minimize manual infrastructure management.
How should the data engineer fulfill these requirements?
- A. Use traditional Spark Structured Streaming with Auto Loader, manually configuring checkpoints location and enabling schema inference with "mergeSchema"= "true"
- B. Use Lakeflow Spark Declarative Pipelines with a static DataFrame read, merge schema with spark.conf.set ("spark.databricks.delta.schema.autoMerge.enabled", "true")
- C. Use Auto Loader in batch mode with a daily job to overwrite the Delta table.
- D. Use Lakeflow Spart Declarative Pipelines with Auto Loader and enabling schema inference with
"cloudFiles.schemaEvolutionMode"= "addNewColumns"
Answer: D
Explanation:
Lakeflow Spark Declarative Pipelines combined with Auto Loader provide fully managed incremental file ingestion with exactly-once guarantees and minimal operational overhead.
Enabling schema inference and evolution allows new columns in incoming JSON files to be incorporated automatically, satisfying the requirements for streaming ingestion, schema evolution, and reduced manual infrastructure management.
NEW QUESTION # 142
The data architect has mandated that all tables in the Lakehouse should be configured as external (also known as "unmanaged") Delta Lake tables.
Which approach will ensure that this requirement is met?
- A. When tables are created, make sure that the EXTERNAL keyword is used in the CREATE TABLE statement.
- B. When data is saved to a table, make sure that a full file path is specified alongside the Delta format.
- C. When a database is being created, make sure that the LOCATION keyword is used.
- D. When configuring an external data warehouse for all table storage, leverage Databricks for all ELT.
- E. When the workspace is being configured, make sure that external cloud object storage has been mounted.
Answer: A
Explanation:
Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from To create an external or unmanaged Delta Lake table, you need to use the EXTERNAL keyword in the CREATE TABLE statement. This indicates that the table is not managed by the catalog and the data files are not deleted when the table is dropped. You also need to provide a LOCATION clause to specify the path where the data files are stored.
For example:
CREATE EXTERNAL TABLE events ( date DATE, eventId STRING, eventType STRING, data STRING) USING DELTA LOCATION `/mnt/delta/events'; This creates an external Delta Lake table named events that references the data files in the
`/mnt/delta/events' path. If you drop this table, the data files will remain intact and you can recreate the table with the same statement.
NEW QUESTION # 143
A data engineering team is configuring access controls in Databricks Unity Catalog. They grant the SELECT privilege on the sales catalog to the analyst_group, expecting that members of this group will automatically have SELECT access to all current and future schemas, tables, and views within the catalog. What describes the privilege inheritance behavior in Unity Catalog?
- A. Privileges in Unity Catalog do not cascade; SELECT must be explicitly granted on each schema and table, even if granted at the catalog level.
- B. Granting SELECT on a catalog automatically applies SELECT to all current and future schemas, tables, and views within that catalog.
- C. Privileges granted at the schema level override any catalog-level privileges and prevent access unless explicitly revoked.
- D. Granting SELECT at the catalog level applies to existing schemas and tables but not to those created in the future.
Answer: A
Explanation:
In Unity Catalog, privileges are non-cascading--meaning that granting a privilege (like SELECT) on a catalog does not automatically grant the same privilege on contained objects (schemas, tables, or views). Each object type has its own independent access control hierarchy.
According to the Databricks access control documentation: "Privileges do not automatically cascade from catalog to schema or table levels." Administrators must explicitly grant privileges on each level if users need access across objects. This design ensures tighter governance and least-privilege enforcement. Therefore, option B correctly describes Unity Catalog's privilege model, while A and D incorrectly imply automatic inheritance.
NEW QUESTION # 144
The data engineering team maintains a table of aggregate statistics through batch nightly updates. This includes total sales for the previous day alongside totals and averages for a variety of time periods including the 7 previous days, year-to-date, and quarter-to-date. This table is named store_saies_summary and the schema is as follows:
The table daily_store_sales contains all the information needed to update store_sales_summary.
The schema for this table is:
store_id INT, sales_date DATE, total_sales FLOAT
If daily_store_sales is implemented as a Type 1 table and the total_sales column might be adjusted after manual data auditing, which approach is the safest to generate accurate reports in the store_sales_summary table?
- A. Implement the appropriate aggregate logic as a batch read against the daily_store_sales table and overwrite the store_sales_summary table with each Update.
- B. Implement the appropriate aggregate logic as a batch read against the daily_store_sales table and use upsert logic to update results in the store_sales_summary table.
- C. Use Structured Streaming to subscribe to the change data feed for daily_store_sales and apply changes to the aggregates in the store_sales_summary table with each update.
- D. Implement the appropriate aggregate logic as a Structured Streaming read against the daily_store_sales table and use upsert logic to update results in the store_sales_summary table.
- E. Implement the appropriate aggregate logic as a batch read against the daily_store_sales table and append new rows nightly to the store_sales_summary table.
Answer: A
NEW QUESTION # 145
A nightly batch job is configured to ingest all data files from a cloud object storage container where records are stored in a nested directory structure YYYY/MM/DD. The data for each date represents all records that were processed by the source system on that date, noting that some records may be delayed as they await moderator approval. Each entry represents a user review of a product and has the following schema:
user_id STRING, review_id BIGINT, product_id BIGINT, review_timestamp TIMESTAMP, review_text STRING The ingestion job is configured to append all data for the previous date to a target table reviews_raw with an identical schema to the source system. The next step in the pipeline is a batch write to propagate all new records inserted into reviews_raw to a table where data is fully deduplicated, validated, and enriched.
Which solution minimizes the compute costs to propagate this batch of data?
Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from
- A. Filter all records in the reviews_raw table based on the review_timestamp; batch append those records produced in the last 48 hours.
- B. Configure a Structured Streaming read against the reviews_raw table using the trigger once execution mode to process new records as a batch job.
- C. Use Delta Lake version history to get the difference between the latest version of reviews_raw and one version prior, then write these records to the next table.
- D. Perform a batch read on the reviews_raw table and perform an insert-only merge using the natural composite key user_id, review_id, product_id, review_timestamp.
- E. Reprocess all records in reviews_raw and overwrite the next table in the pipeline.
Answer: B
Explanation:
https://www.databricks.com/blog/2017/05/22/running-streaming-jobs-day-10x-cost-savings.html
NEW QUESTION # 146
The Databricks CLI is use to trigger a run of an existing job by passing the job_id parameter. The response that the job run request has been submitted successfully includes a filed run_id.
Which statement describes what the number alongside this field represents?
- A. The globally unique ID of the newly triggered run.
- B. The total number of jobs that have been run in the workspace.
- C. The job_id and number of times the job has been are concatenated and returned.
- D. The number of times the job definition has been run in the workspace.
- E. The job_id is returned in this field.
Answer: A
Explanation:
When triggering a job run using the Databricks CLI, the run_id field in the response represents a globally unique identifier for that particular run of the job. This run_id is distinct from the job_id.
While the job_id identifies the job definition and is constant across all runs of that job, the run_id is unique to each execution and is used to track and query the status of that specific job run within the Databricks environment. This distinction allows users to manage and reference individual executions of a job directly.
NEW QUESTION # 147
A company wants to implement Lakehouse Federation across multiple data sources but is concerned about data consistency and ensuring that all teams access the same authoritative version of their data. Which statement is applicable for Lakehouse Federations to maintain data consistency?
- A. Federation creates local copies that must be manually refreshed.
- B. A separate data synchronization service must be deployed.
- C. Federation provides read-only access that reflects the current state of source systems.
- D. Federation implements change data capture (CDC) from all sources.
Answer: C
Explanation:
Lakehouse Federation allows Databricks to query and manage external data sources through a single governance layer, without moving or copying data. The documentation specifies that
"Federated queries provide read-only access to data, reflecting the current state of the underlying source system." This ensures consistency across teams since all users access the same source of truth directly from the external system through Unity Catalog. Federation does not perform CDC replication or local caching; it queries live data on demand. Hence, option A accurately represents how Lakehouse Federation maintains consistency across federated sources.
NEW QUESTION # 148
Which statement describes Delta Lake optimized writes?
- A. A shuffle occurs prior to writing to try to group data together resulting in fewer files instead of each executor writing multiple files based on directory partitions.
- B. An asynchronous job runs after the write completes to detect if files could be further compacted; yes, an OPTIMIZE job is executed toward a default of 1 GB.
- C. Before a job cluster terminates, OPTIMIZE is executed on all tables modified during the most recent job.
- D. Optimized writes logical partitions instead of directory partitions partition boundaries are only Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from represented in metadata fewer small files are written.
Answer: A
Explanation:
Delta Lake optimized writes involve a shuffle operation before writing out data to the Delta table.
The shuffle operation groups data by partition keys, which can lead to a reduction in the number of output files and potentially larger files, instead of multiple smaller files. This approach can significantly reduce the total number of files in the table, improve read performance by reducing the metadata overhead, and optimize the table storage layout, especially for workloads with many small files.
NEW QUESTION # 149
A junior data engineer is working to implement logic for a Lakehouse table named silver_device_recordings. The source data contains 100 unique fields in a highly nested JSON Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from structure.
The silver_device_recordings table will be used downstream for highly selective joins on a number of fields, and will also be leveraged by the machine learning team to filter on a handful of relevant fields, in total, 15 fields have been identified that will often be used for filter and join logic.
The data engineer is trying to determine the best approach for dealing with these nested fields before declaring the table schema.
Which of the following accurately presents information about Delta Lake and Databricks that may Impact their decision-making process?
- A. Tungsten encoding used by Databricks is optimized for storing string data: newly-added native support for querying JSON strings means that string types are always most efficient.
- B. Because Delta Lake uses Parquet for data storage, Dremel encoding information for nesting can be directly referenced by the Delta transaction log.
- C. By default Delta Lake collects statistics on the first 32 columns in a table; these statistics are leveraged for data skipping when executing selective queries.
- D. Schema inference and evolution on Databricks ensure that inferred types will always accurately match the data types used by downstream systems.
Answer: C
Explanation:
Delta Lake, built on top of Parquet, enhances query performance through data skipping, which is based on the statistics collected for each file in a table. For tables with a large number of columns, Delta Lake by default collects and stores statistics only for the first 32 columns. These statistics include min/max values and null counts, which are used to optimize query execution by skipping irrelevant data files. When dealing with highly nested JSON structures, understanding this behavior is crucial for schema design, especially when determining which fields should be flattened or prioritized in the table structure to leverage data skipping efficiently for performance optimization.
NEW QUESTION # 150
Although the Databricks Utilities Secrets module provides tools to store sensitive credentials and avoid accidentally displaying them in plain text users should still be careful with which credentials are stored here and which users have access to using these secrets.
Which statement describes a limitation of Databricks Secrets?
- A. Secrets are stored in an administrators-only table within the Hive Metastore; database administrators have permission to query this table by default.
- B. Account administrators can see all secrets in plain text by logging on to the Databricks Accounts console.
- C. Because the SHA256 hash is used to obfuscate stored secrets, reversing this hash will display Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from the value in plain text.
- D. The Databricks REST API can be used to list secrets in plain text if the personal access token has proper credentials.
- E. Iterating through a stored secret and printing each character will display secret contents in plain text.
Answer: D
Explanation:
This is the correct answer because it describes a limitation of Databricks Secrets. Databricks Secrets is a module that provides tools to store sensitive credentials and avoid accidentally displaying them in plain text. Databricks Secrets allows creating secret scopes, which are collections of secrets that can be accessed by users or groups. Databricks Secrets also allows creating and managing secrets using the Databricks CLI or the Databricks REST API. However, a limitation of Databricks Secrets is that the Databricks REST API can be used to list secrets in plain text if the personal access token has proper credentials. Therefore, users should still be careful with which credentials are stored in Databricks Secrets and which users have access to using these secrets.
NEW QUESTION # 151
A data engineering team needs to implement a tagging system for their tables as part of an automated ETL process, and needs to apply tags programmatically to tables in Unity Catalog.
Which SQL command adds tags to a table programmatically?
- A. COMMENT ON TABLE table_name TAGS ('key1' = 'value1', 'key2' = 'value2');
- B. APPLY TAGS ON table_name VALUES ('key1' = 'value1', 'key2' = 'value2');
- C. SET TAGS FOR table_name AS ('key1' = 'value1', 'key2' = 'value2');
- D. ALTER TABLE table_name SET TAGS ('key1' = 'value1', 'key2' = 'value2');
Answer: D
Explanation:
Unity Catalog supports programmatic tagging through the ALTER TABLE statement. Using SET TAGS allows tags to be added or updated directly on a table as part of automated ETL workflows, making it the correct and supported SQL command for managing table tags.
NEW QUESTION # 152
A data ingestion task requires a one-TB JSON dataset to be written out to Parquet with a target Get Latest & Actual Certified-Data-Engineer-Professional Exam's Question and Answers from part- file size of 512 MB. Because Parquet is being used instead of Delta Lake, built-in file-sizing features such as Auto-Optimize & Auto-Compaction cannot be used.
Which strategy will yield the best performance without shuffling data?
- A. Set spark.sql.shuffle.partitions to 2,048 partitions (1TB*1024*1024/512), ingest the data, execute the narrow transformations, optimize the data by sorting it (which automatically repartitions the data), and then write to parquet.
- B. Set spark.sql.adaptive.advisoryPartitionSizeInBytes to 512 MB bytes, ingest the data, execute the narrow transformations, coalesce to 2,048 partitions (1TB*1024*1024/512), and then write to parquet.
- C. Set spark.sql.files.maxPartitionBytes to 512 MB, ingest the data, execute the narrow transformations, and then write to parquet.
- D. Set spark.sql.shuffle.partitions to 512, ingest the data, execute the narrow transformations, and then write to parquet.
- E. Ingest the data, execute the narrow transformations, repartition to 2,048 partitions (1TB*
1024*1024/512), and then write to parquet.
Answer: A
Explanation:
The key to efficiently converting a large JSON dataset to Parquet files of a specific size without shuffling data lies in controlling the size of the output files directly. Setting spark.sql.files.maxPartitionBytes to 512 MB configures Spark to process data in chunks of 512 MB. This setting directly influences the size of the part-files in the output, aligning with the target file size.
Narrow transformations (which do not involve shuffling data across partitions) can then be applied to this data.
Writing the data out to Parquet will result in files that are approximately the size specified by spark.sql.files.maxPartitionBytes, in this case, 512 MB. The other options involve unnecessary shuffles or repartitions (B, C, D) or an incorrect setting for this specific requirement (E).
NEW QUESTION # 153
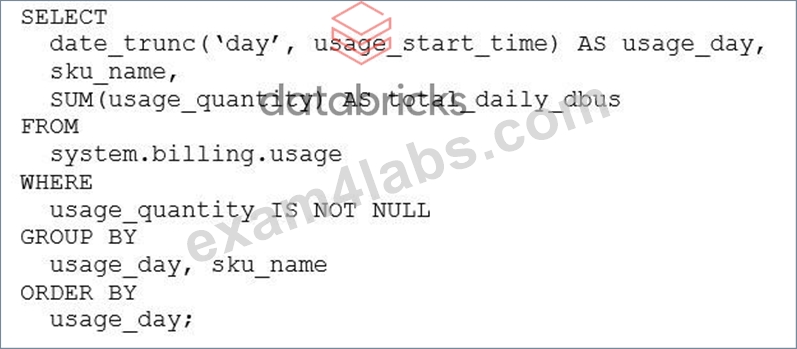
A platform engineer needs to report the resource consumption, categorized by SKU tier, across all workspaces. The engineer decides to use the system.billing.usage system table to create a query. Which SQL query will accurately return the daily usage by product?
- A.
- B.

- C.

- D.

Answer: A
Explanation:
This query correctly aggregates usage at a daily granularity by truncating the usage start timestamp to the day and summing the usage quantity, which represents DBUs. Grouping by both the derived daily value and the SKU name ensures usage is accurately categorized by product tier across all workspaces.
NEW QUESTION # 154
A data engineer is designing a system to process batch patient encounter data stored in an S3 bucket, creating a Delta table (patient_encounters) with columns encounter_id, patient_id, encounter_date, diagnosis_code, and treatment_cost. The table is queried frequently by patient_id and encounter_date, requiring fast performance. Fine-grained access controls must be enforced. The engineer wants to minimize maintenance and boost performance. How should the data engineer create the patient_encounters table?
- A. Create a managed table in Hive Metastore. Configure Hive Metastore permissions for access controls, and rely on predictive optimization to enhance query performance and simplify maintenance.
- B. Create an external table in Unity Catalog, specifying an S3 location for the data files. Enable predictive optimization through table properties, and configure Unity Catalog permissions for access controls.
- C. Create a managed table in Unity Catalog. Configure Unity Catalog permissions for access controls, and rely on predictive optimization to enhance query performance and simplify maintenance.
- D. Create a managed table in Unity Catalog. Configure Unity Catalog permissions for access controls, schedule jobs to run OPTIMIZE and VACUUM commands daily to achieve best performance.
Answer: C
Explanation:
Databricks documentation specifies that Unity Catalog managed tables are the preferred choice for secure, low-maintenance Delta Lake architectures. Managed tables provide full lifecycle management, including metadata, file storage, and access control integration with Unity Catalog.
Fine-grained permissions can be enforced at the column and row level through built-in Unity Catalog governance.
Additionally, Predictive Optimization (Auto Optimize + Auto Compaction) automatically manages file sizes, metadata pruning, and layout optimization, eliminating the need for manual maintenance such as scheduling OPTIMIZE or VACUUM.
External tables (A) require manual path management, and Hive Metastore tables (D) do not support Unity Catalog access policies. Therefore, creating a managed Unity Catalog table with predictive optimization provides both the security and performance benefits needed, making B the correct solution.
NEW QUESTION # 155
The view updates represents an incremental batch of all newly ingested data to be inserted or updated in the customers table.
The following logic is used to process these records.
Which statement describes this implementation?
- A. The customers table is implemented as a Type 3 table; old values are maintained as a new column alongside the current value.
- B. The customers table is implemented as a Type 2 table; old values are overwritten and new customers are appended.
- C. The customers table is implemented as a Type 1 table; old values are overwritten by new values and no history is maintained.
- D. The customers table is implemented as a Type 0 table; all writes are append only with no changes to existing values.
- E. The customers table is implemented as a Type 2 table; old values are maintained but marked as no longer current and new values are inserted.
Answer: E
NEW QUESTION # 156
A small company based in the United States has recently contracted a consulting firm in India to implement several new data engineering pipelines to power artificial intelligence applications. All the company's data is stored in regional cloud storage in the United States.
The workspace administrator at the company is uncertain about where the Databricks workspace used by the contractors should be deployed.
Assuming that all data governance considerations are accounted for, which statement accurately informs this decision?
- A. Databricks notebooks send all executable code from the user's browser to virtual machines over the open internet; whenever possible, choosing a workspace region near the end users is the most secure.
- B. Cross-region reads and writes can incur significant costs and latency; whenever possible, compute should be deployed in the same region the data is stored.
- C. Databricks workspaces do not rely on any regional infrastructure; as such, the decision should be made based upon what is most convenient for the workspace administrator.
- D. Databricks leverages user workstations as the driver during interactive development; as such, users should always use a workspace deployed in a region they are physically near.
- E. Databricks runs HDFS on cloud volume storage; as such, cloud virtual machines must be deployed in the region where the data is stored.
Answer: B
Explanation:
This is the correct answer because it accurately informs this decision. The decision is about where the Databricks workspace used by the contractors should be deployed. The contractors are based in India, while all the company's data is stored in regional cloud storage in the United States. When choosing a region for deploying a Databricks workspace, one of the important factors to consider is the proximity to the data sources and sinks. Cross-region reads and writes can incur significant costs and latency due to network bandwidth and data transfer fees.
Therefore, whenever possible, compute should be deployed in the same region the data is stored to optimize performance and reduce costs.
NEW QUESTION # 157
Two data engineers are working on the same Databricks notebook in separate branches. Both have edited the same section of code. When one tries to merge the other's branch into their own using the Databricks Git folders UI, a merge conflict occurs on that notebook file. The UI highlights the conflict and presents options for resolution. How should the data engineers resolve this merge conflict using Databricks Git folders?
- A. Use the Git folders UI to manually edit the notebook file, selecting the desired lines from both versions and removing the conflict markers, then mark the conflict as resolved.
- B. Use the Git CLI in the cluster's web terminal to force-push the conflicted merge (git push -force), overriding the remote branch with the local version and discarding changes.
- C. Delete the conflicted notebook file via the Databricks workspace UI, commit the deletion, and recreate the notebook from scratch in a new commit to bypass the conflict entirely.
- D. Abort the merge, discard all local changes, and try the merge operation again without reviewing the conflicting code.
Answer: A
Explanation:
In the Databricks Git folders integration, when merge conflicts arise in notebooks, the UI provides a visual diff editor that highlights conflicting code segments. Users can manually choose which changes to keep from each branch, edit directly in the notebook UI, and remove conflict markers.
After resolving, the engineer must mark the conflict as resolved, save, and commit the final version.
This process ensures that both contributors' valid code segments are merged correctly and version history is maintained.
Forcing a push (C) or deleting notebooks (B) introduces data loss or versioning issues. Aborting without review (A) violates collaborative best practices. Therefore, D is the only correct and Databricks-approved way to resolve notebook merge conflicts.
NEW QUESTION # 158
......
Authentic Best resources for Databricks-Certified-Data-Engineer-Professional Online Practice Exam: https://www.exam4labs.com/Databricks-Certified-Data-Engineer-Professional-practice-torrent.html